网页数据解析及抽取-parsel
发布时间丨2023-02-25 11:39:50作者丨zhaomeng浏览丨0
什么是 Parsel
Parsel 是一个基于 lxml 的快速、灵活且可扩展的 HTML/XML 解析库,它可以帮助我们轻松地从一个页面中提取出所需数据。Parsel 封装了 Python 中常用的 Selectors、XPath 和 CSS 样式选择器等语法,使得开发者能够更加灵活地定义、过滤和提取 HTML 内容。
安装 Parsel
安装 Parsel 可以使用 pip 指令,示例如下:
pip install parsel
安装完成后,在 Python 中即可导入 Parsel 和相关依赖库:
from parsel import Selector
import requests
然后,我们可以使用 requests 库先请求需要解析的 HTML 或 XML 页面:
url = 'https://www.example.com'
response = requests.get(url)
Parsel 进行网页数据解析
下面通过一个简单的例子来说明如何使用 Parsel 来进行网页数据解析和抽取。我们将从一个网站获取电影列表的名称、评分和导演信息。
首先,访问该网站并检查其 HTML 结构或元素定位方式。在此示例中,我们以 IMDb Top 250 页面为例。打开网页后,可以看到电影列表的 HTML 结构 如下图所示:
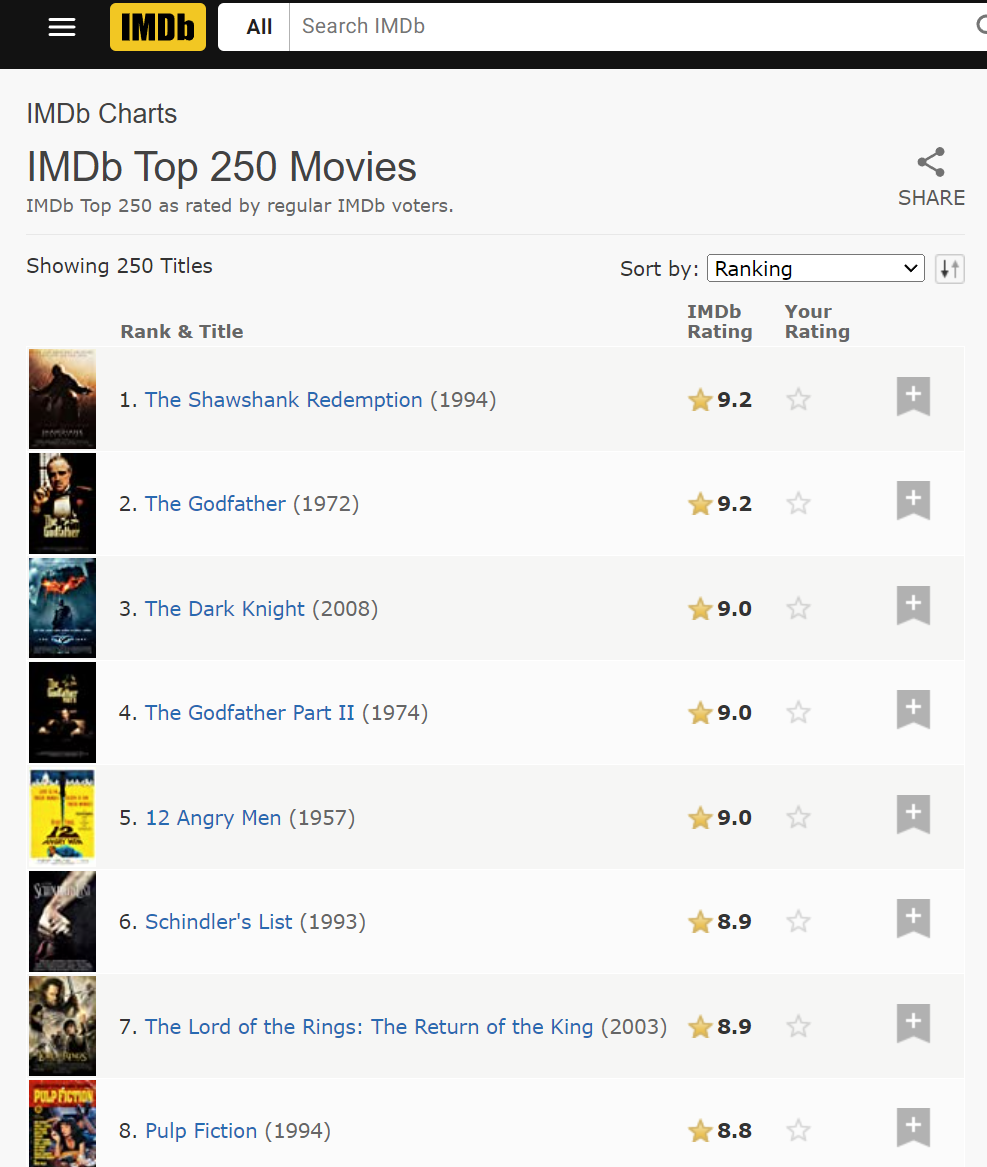
通过检查 HTML 元素,我们可以发现电影名称、评分和导演信息等分别存储在 div.list.detail 和 td.ratingColumn 和 a 三个 HTML 标签中。接下来,根据此结构和特点,我们即可使用 Parsel 对这些数据进行抽取。
from parsel import Selector
response = requests.get(url)
selector = Selector(response.text)
movies = selector.css('tbody.lister-list tr')
for movie in movies:
title = movie.css('td.titleColumn a::text').extract_first().strip()
director = movie.css('td.titleColumn a::attr(href)').re('/name/nm\d+')[0]
rating = movie.css('td.ratingColumn strong::text').extract_first()
print(f'Title: {title}')
print(f'Director ID: {director}')
print(f'Rating: {rating}\n')
执行以上代码,输出则如下所示:
Title: The Shawshank Redemption
Director ID: nm0001104
Rating: 9.3
Title: The Godfather
Director ID: nm0000338
Rating: 9.2
Title: The Dark Knight
Director ID: nm0634240
Rating: 9.0
...
通过上述示例,我们可以看到利用 Parsel 和相关语法选择器,轻松实现了对 IMDb Top 250 中电影信息的抽取,并可进行后续处理和分析。
总结
Parsel 是一个高效、灵活、易用、可扩展的 Python HTML/XML 解析库。它封装了许多常用的选择器语法,可以有效地提高开发者在解析网页数据时的效率和准确性。同时,Parsel 的架构和 API 设计也使得其具有良好的可维护性和扩展性,最大化地提供了定位、筛选和提取目标数据的自由度和功能。
如果要获取页面中的所需数据,使用 Parsel 及相关工具进行数据抓取并进行分析处理,将是一种十分便捷和高效的方式。